Tutorial_0813_kaggle Titanic
1. 스프레드시트로 캐글 참여하기
(1) 캐글 사이트에서 train.csv와 test.csv를 다운로드 받습니다.
(2) 구글 스프레드 시트에 titanic 폴더를 하나 생성하고 파일을 올립니다.
(3) train.csv 시트를 열어 봅니다.
(4) train.csv 시트에서 피봇테이블로 각 항목별 생존률을 봅니다.
예) 성별, 등급, 가족, 탑승지 등에 따라 생존률을 봅니다.

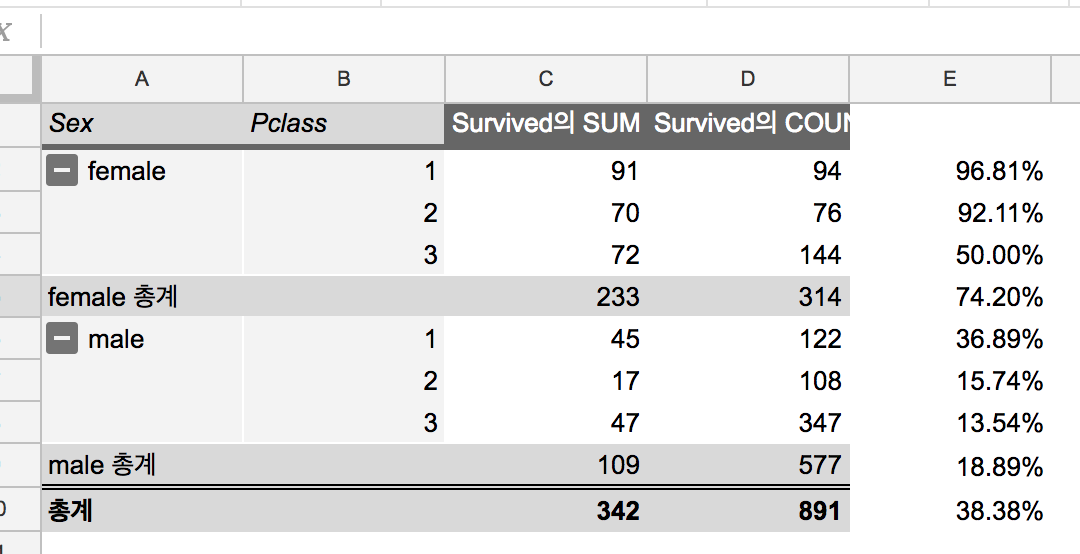
(5) train.csv 의 피봇테이블에서 본 데이터를 바탕으로
(6) test.csv 파일에서 스프레드시트의 수식기호를 사용해 생존자를 구해봅니다.
생존했을 때 1, 그렇지 못했을 때 0으로 표시합니다. 예) =IF(E3="female", 1, 0)전체행에 수식을 적용하는 것은 수식이 있는 첫번째 셀의 작은 네모에 마우스를 가져가면 + 표시가 생깁니다. 이 표시를 더블클릭하면 전체 행에 수식이 적용됩니다.

(7) submission 파일을 만들어 제출합니다. 이때, submission 파일의 형식은 캐글 사이트에서 다운로드 받은 것과 같은 형식이어야 합니다. 다음과 같은 2개의 컬럼을 가지며 컬럼명이 일치해야 합니다.PassengerIdSurvived
(8) 새로운 시트를 만들어 수식을 제외한 값만 붙여넣기 해서 제출 파일을 만듭니다.

(9) 조별 실습을 통해 데이터를 보고 생존률을 머신러닝이 아닌 집단지성을 통해 해결해 봅니다.
(10) 스프레드시트의 수식으로 집단지성을 구현해 보고 캐글에 제출하고 어느 조가 가장 높은 점수를 얻는지 공유해 보도록 해요.
2. 파이썬으로 분석하기
엑셀로 분석했던 과정을 똑같이 파이썬으로 해봅니다.
(1) train, test.csv 파일불러오기
(2) 엑셀에서 했던 것 처럼 pivot 테이블 만들어 분석해 보기
(3) 파이썬 코드로 엑셀에서 했던 과정을 똑같이 해보기
(4) submission.csv 파일 생성해서 제출해 보기
# 성별에 따른 생존률
# 생존여부가 1과 0으로 되어 있기 때문에 평균을 구하면 생존률이 된다.
# groupby로 구하기train.groupby('Sex')[['Survived']].mean()
# pivot_table로 구하기train.pivot_table(values=['Survived'], index=['Sex'], aggfunc=np.mean)
# 성별, 선실등급별 생존률
train.pivot_table('Survived', ['Sex', 'Pclass'], aggfunc=np.mean)
# 캐글 제출용 파일 만들기submission.to_csv('submissions/submission.csv', index=False)
3. 실습 내용 정리
import pandas as pd
import numpy as np
데이터를 불러오기
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
print(train.shape)
print(test.shape)
데이터 요약하기 (describe과 info)
train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
성별에 따른 생존률
생존여부가 1과 0으로 되어 있기 때문에 평균을 구하면 생존률이 됩니다.
train.groupby('Sex')[['Survived']].mean()
| Survived | |
|---|---|
| Sex | |
| female | 0.742038 |
| male | 0.188908 |
train.pivot_table(values=['Survived'], index=['Sex'], aggfunc=np.mean)
| Survived | |
|---|---|
| Sex | |
| female | 0.742038 |
| male | 0.188908 |
train.pivot_table(index=['Sex'])
| Age | Fare | Parch | PassengerId | Pclass | SibSp | Survived | |
|---|---|---|---|---|---|---|---|
| Sex | |||||||
| female | 27.915709 | 44.479818 | 0.649682 | 431.028662 | 2.159236 | 0.694268 | 0.742038 |
| male | 30.726645 | 25.523893 | 0.235702 | 454.147314 | 2.389948 | 0.429809 | 0.188908 |
# 성별의 4분위수를 보는것은 의미는 없습니다. 다만, describe를 써서 다음과 같은 형태의 분석도 가능하다는 예시입니다.
train.groupby('Sex')[['Survived']].describe()
| Survived | ||||||||
|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | |
| Sex | ||||||||
| female | 314.0 | 0.742038 | 0.438211 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| male | 577.0 | 0.188908 | 0.391775 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
# 성별, 선실등급별 생존률
train.pivot_table('Survived', ['Sex', 'Pclass'], aggfunc=np.mean)
| Survived | ||
|---|---|---|
| Sex | Pclass | |
| female | 1 | 0.968085 |
| 2 | 0.921053 | |
| 3 | 0.500000 | |
| male | 1 | 0.368852 |
| 2 | 0.157407 | |
| 3 | 0.135447 |
train.groupby('Sex')[['Survived']].mean()
| Survived | |
|---|---|
| Sex | |
| female | 0.742038 |
| male | 0.188908 |
엑셀에서 했던것과 동일하게 여성일 때 생존했다고 가정하고 Survived 데이터를 채워줍니다.
test['Survived'] = (test.Sex == 'female') & (test.Age > 0) & (test.Embarked )
test.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | False | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q |
| 1 | 893 | True | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S |
| 2 | 894 | False | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q |
| 3 | 895 | False | 3 | Wirz, Mr. Albert | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S |
| 4 | 896 | True | 3 | Hirvonen, Mrs. Alexander (Helga E Lindqvist) | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S |
test.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
test['Survived'].value_counts()
False 291
True 127
Name: Survived, dtype: int64
pandas의 데이터프레임 복사에 대해 이해합니다.
참고 Understanding SettingwithCopyWarning in pandas
submission = test[['PassengerId', 'Survived']].copy()
submission.head()
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | False |
| 1 | 893 | True |
| 2 | 894 | False |
| 3 | 895 | False |
| 4 | 896 | True |
제출형태에 맞는 데이터 타입으로 변경해 줍니다.
submission['Survived'] = submission['Survived'].astype(int)
submission.head()
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 1 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
csv 형태로 파일을 만듭니다.
# %mkdir submissions
submission.to_csv('submissions/submission.csv', index=False)
탐색기 혹은 Finder에서 제출파일을 얻어 제출하기 위해 경로를 얻어옵니다.
%pwd