2018.08.10 데잇걸즈 TWL : 아파트 분양가 분석, 회귀분석
오전 : 아파트 분양가/공원 정보 분석하기
(수업) 아파트 분양가 정보 분석하기
자료 출처 : 공공데이터포털 전국 신규 민간 아파트 분양가격 동향 정보 (csv file 다운로드)
GitHub Repository 및 Local 작업용 폴더 생성 : .gitignore 파일도 추가 생성 (open-data-apt 바로 밑 경로에 생성)
git으로 관리하지 않을 파일 목록 삽입
# .gitignore 파일 코드 .ipynb_checkpoints/ *.csv *.tsv *.zip데이터 확인, Tidy 처리 (@ Jupyter Notebook) : 칼럼(기준) 통일, 결측치 정리 등
데이터 분석 / 시각화 (@ Jupyter Notebook) : 연도별/지역별 평당 분양가, 등락 정도 등
결과물을 Github에 Add / Commit / Push
(개인별 실습) 공원 정보 분석하기
자료 출처 : 공공데이터포털 전국 도시공원 표준데이터
GitHub Repository 및 Local 작업용 폴더 생성 : .gitignore 파일도 추가 생성
# .gitignore 파일 코드 .ipynb_checkpoints/ .csv .tsv .zip데이터 확인, Tidy 처리 (@ Jupyter Notebook) : 칼럼(기준) 통일, 결측치 정리 등
데이터 분석 / 시각화 (@ Jupyter Notebook) : 지역별/종류별 공원 분포 현황 등
결과물을 Github에 Add / Commit / Push
오후 : Statistics5 / 회귀분석
분산분석
- ANOVA (Analysis of Variance)
- 3개 이상의 집단에 대한 평균 차이를 검정하기 위해서, 분산을 비교하는 분석 방법
- 집단 간의 분산과 집단 내의 분산을 확인하여 모집단의 특성을 찾아냄
- 총편차 = 집단 간 편차 + 집단 내 편차
- 집단 간의 분산이 클수록, 집단 내의 분산이 작을수록 집단 간의 평균차이가 커짐
- 분산비율 F
- 집단 간의 상대적인 비율을 확인한 것
- 분산비율 F = 집단 간 변동 / 집단 내 변동
- F값이 커질수록 집단간의 평균차이가 커짐
분산분석표
자유도(Degrees of freedom) : 모집단에 대한 정보를 주는 독립적인 자료의 수
F분포 : 두 개의 자유도에 따라서 값이 달라짐
Python 환경에서의 ANOVA 분석 : scipy.stats.f_oneway()
# scipy.stats.f_oneway() # Starbucks, Ediya, Twosome의 데이터가 각각 개별 칼럼으로 정리되어 있을때 # Output : F-statistics, p_value from scipy import stats stats.f_oneway(choco['starbucks'], choco['ediya'], choco['twosome']) # Boxplot을 그려보자 choco = choco.astype('int') # 우선 형 변환을 하고 choco.boxplot() # Boxplot을 생성# ols() + anava_lm() # Starbucks, Ediya, Twosome의 데이터가 전부 하나의 칼럼으로 정리되어 있을때 import statsmodels.api as sm from statsmodels.formula.api import ols model = ols("kcal ~ coffee", choco2).fit() sm.stats.anova_lm(model, typ=2) choco2['kcal'] = choco2['kcal'].astype(int) choco2.boxplot('kcal', by='coffee')
상관분석
상관분석 : 두 개의 연속형 변수에 대해서, 상관계수를 이용하여 선형 관계를 분석
상관계수
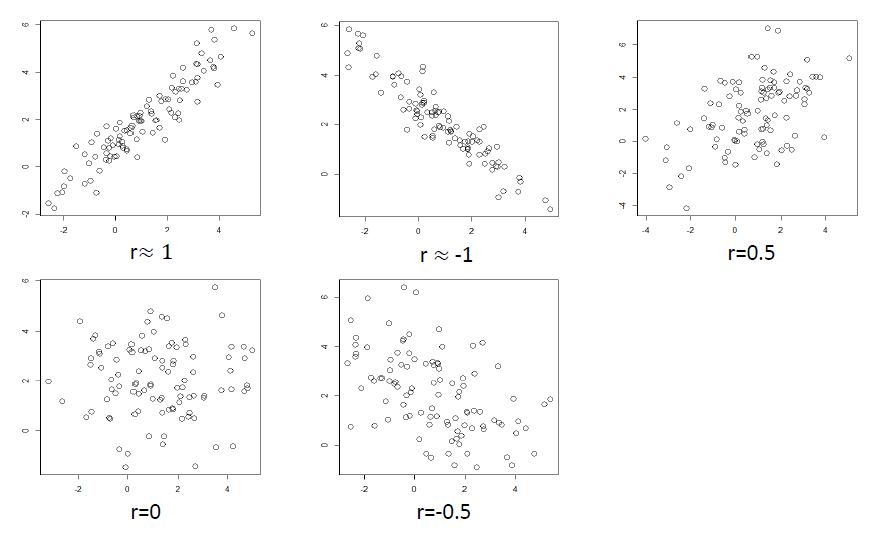
- 범위 : -1 <= r <= 1
- r이 양수이면 양의 상관관계, 음수이면 음의 상관관계를 의미
- 값의 크기는 선형관계의 강도를 의미 (1 = 완벽한 선형관계, 0 = 선형관계 없음)
상관계수는 꼭 산점도와 함께 계산 필요 : 비선형의 경우 상관계수만으로는 알 수 없음
산점도 상으로는 변수 간의 선형관계가 보이지 않으나 상관계수의 값이 높게 나온 경우
- 아웃라이어 때문에 상관계수의 값이 비정상적으로 높게 나온 경우일 수 있음
- 해결법 : 아웃라이어 제거 or log 변환 후 상관계수/산점도 구해 보기
상관분석 가설/검정
- 귀무가설 : 상관계수 = 0, 두 자료의 상관관계가 있다.
- 대립가설 : 상관계수 ≠ 0, 두 자료의 상관관계가 있다.
- 두 개의 연속형 변수의 모집단에서 상관계수가 0인지를 검정
- 결과 해석 : 검정 결과 p-value가 유의수준보다 작을 경우, 귀무가설을 기각
Python 환경에서의 상관계수 분석 : scipy.stats.perasonr()
from scipy import stats pulse = np.array([69,68,70]) height = np.array([172,165,175]) plt.scatter(pulse, height) # output : corr, p_value stats.pearsonr(pulse, height) # df.corr() : 데이터프레임으로 입력한 경우 np.corrcoef(pulse, height) : array로 입력한 경우
회귀분석
'회귀'(regression) : 옛날 상태로 돌아감
회귀분석(linear regression)
- 두 변수(독립변수/종속변수) 사이의 통계적 유의미성을 검증, 관계의 정도를 분석
- x = 독립변수, 설명변수 / y = 종속변수, 반응변수
선형회귀분석 : 가지고 있는 데이터를 직선 형태로 나타내는 선을 찾음
- 단순 선형 회귀분석 : 설명변수가 1개인 선형회귀모형
- 다중 선형 회귀분석 : 설명변수가 2개 이상인 선형회귀모형
선형 : 그래프가 직선으로 나타남 / 비선형 : 직선이 아닌 함수
회귀식 구하기
- 실제 회귀선과 가장 적게 차이가 나는 회귀선을 추정 : 오차를 최소화하는 회귀식 도출
- 최소 제곱 추정법 : 모든 관측치의 실제 값 - 예측한 값의 제곱을 합해서 가장 작은 회귀식 선택
지시변수 : 범주형 변수의 처리를 위해, (class의 갯수 -1) 개의 1,0으로 구성된 변수로 전환시킨 변수
모형의 적합도, 설명력 : 결정계수 (R-square)
- 결정계수 : X가 Y를 얼마나 설명하는지에 대한 정보 제공 (= 회귀식은 얼마나 정확한가?)
- 반응변수의 전체변동 중 예측변수가 차지하는 변동의 비율
- 결정계수 = 1 : 회귀직선으로 Y를 완전히 설명 가능. 회귀식의 정확도 매우 높음.
- 결정계수 = 0. 추정된 회귀직선은 X와 Y의 관계 설명 불가. 회귀식의 정확도 매우 낮음.
Python 환경에서의 회귀분석
# 1번 방법 # 장점 : x, y 지정이 가능함 # 단점 : x, y 지정을 해줘야만 사용 가능 & 범주형 변수는 범위형 변수로 사전에 변환해야 함 import statsmodels.api as sm y = df['y'] x = df[['x1', 'x2', 'x3']] # add_constants(x) : 절편값을 함께 출력 model = sm.OLS(y, sm.add_constants(x)).fit() model.summary()# 2번 방법 # 장점 : x, y 지정이 필요없음 (= 간단함) & 범주형 변수 처리가 간편함 # 범주형(category) 변수를 명시해주고 싶다면 C(변수명)으로 표기하면 됨 # 단점 : x, y 지정 과정이 없음 (= 독립변수의 종류가 많으면 독립변수마다 일일이 적어줘야 함) from statsmodels.formula.api import ols model = ols(formula = "y~ x1 + x2 + x3", data = df).fit() model.summary()예측 그래프 : 실제 종속변수와 예측값의 산점도를 그려서 Y = X의 형태에 가까울수록 예측이 잘 된 것.
predictions = model.predict(X) df = pd.DataFrame({'Actual':boston['medv'], 'Predicted':predictions}) plt.scatter(x = df['Actual'], y = df['Predicted']) plt.plot(np.arrange(0, 50), np.arange(0, 50), color = "red") plt.show()회귀분석의 가정
- 선형성 : x와 y는 선형관계임. 그림을 통해 파악.
- 정규성
- 각 x값에 대하여 모집단에서의 y값은(= 오차는) 정규분포를 따른다
- y값 분포의 분산은 모든 x값에서 같다.
- 히스토그램을 그려본 후 정규분포 모양을 띄는지 확인
- 애매한 경우 : Q-Q plot (quantile-quantile plot)을 그려본 후 직선 위에 위치하는 지 확인
- Q-Q plot : 두 자료의 분위수(quantile)를 확인한 후, 두 자료의 분포가 일치하는지를 확인
- Q-Q plot에서 직선 위에 점들이 모여있다면 데이터는 정규분포를 따른다고 할 수 있음
- 다중공선성 없음
- 다중공선성 : 독립변수들 간에 상관관계가 나타나는 경우
- 회귀분석은 다중공선성 해당 없는 것을 가정함 (= 독립변수(x) 상호 간에는 상관관계가 없음)
다중공선성
- 독립변수(x) 사이의 상관계수가 높은 상황
- 다중공선성으로 인해 발생하는 문제
- 회귀계수의 분산이 커짐
- 즉, 유의한 회귀계수가 유의하지 않다고 판단될 수 있음
- 해결 방법
- 상관관계가 높은 독립변수 중 하나 혹은 일부를 제거
- 변수를 변환
- PCA 방법을 이용해 공선성을 제거 (but PCA 방법은 자료의 의미를 바꿈 : 해석이 불가)
Python 환경에서의 회귀분석 가정 확인
# 선형성 확인 # n차원의 그래프는 그리기도, 해석도 어려움 : 각각의 산점도를 확인하는 방법을 사용 # options # color : scatter plot의 색 결정 # diagonal : 'hist' = histogram, 'kde' = kernel density estimation, default is 'hist' pd.scatter_matrix(boston, figsize = (15,15), color = "grey", diagonal = 'hist') # pd.scatter_matrix(boston, figsize = (15,15), color = "grey", diagonal = 'kde') plt.show()# 정규성 확인 # 끝부분이 애매한 경우 log 변환 진행 boston['medv'].hist() log_y = np.log(y+1) log_y.hist()# 정규성 확인 : 히스토그램 결과가 애매할 때 # Q-Q plot으로 y가 정규분포를 따르는지 확인 가능 import scipy.stats as stats y = boston['medv'].astype(float) stats.probplot(y, dist="norm", plot=plt) plt.title("Normal Q-Q Plot") plt.show() # log 변환하면 좀 더 정규분포스러운 결과가 나올 수 있음 # 이러고도 정규분포를 따르는지 애매하다면 가설검정을 이용해야 함 stats.probplot(log_y, dist="norm", plot=plt) plt.title("log_y Normal Q-Q Plot") plp.show()# 다중공선성 확인 # 상관계수는 연속형 변수끼리만 계산 가능 : 더미변수(범주형 변수)는 제거 # Correlation 시각화 : 히트맵 형태의 그림이 나옴 corrmat = corr_df.corr() # 그림 사이즈 키우기 (안하면 작게 나옴) plt.figure(figsize = (10, 10)) sns.heatmap(corrmat, square = True) plt.show() # Correlation이 0.8보다 큰 쌍들을 찾기 corrmat = corr_df.corr().abs() np.where((corrmat > 0.8) & (corrmat != 1))
회귀분석 - 변수선택
변수선택의 필요성
유의하지 않는 변수들이 존재하는 경우 : Simple is Best
독립변수의 수가 지나치게 많다면, 특히 독립변수들 간의 상관성이 높아진다면 결과가 틀어짐.
유의하지 않은 변수들도 계속 사용해야 함
차원의 저주 : overfitting이 발생
< 차원의 저주 >
차원이 늘어남에 따라 가지고 있는 데이터의 양이 상대적으로 부족하게 됨.
따라서, 적은 데이터로 공간을 설명해야 하기 때문에 overfitting이 발생함.
overfitting이 발생하면 일반화가 안되기 때문에 모델의 성능이 떨어짐.
변수선택의 방법
전진선택법 : 설명변수가 하나도 없는 모델에서 시작하여 가장 유의미한 변수를 하나씩 추가함
후진제거법 : 모든 변수를 사용하여 구축한 모델에서 유의미하지 않는 변수를 하나씩 제거해 감
단계적 선택법 : 설명변수가 하나도 없는 모델에서 시작, 전진선택법/후진소거법을 번갈아가며 수행
단, 유의미한 변수에 대한 기준은 본인이 정해야 함
# 회귀분석 - 변수선택법 예제 정답 전진선택법 : y~x1 → y~x1+x2 → Stop 후진선택법 : y~x1+x2+x3+x4 → y~x1+x2+x3 → y~x2+x3 → Stop 단계적선택법 : y~x1(전진) → y~x1+x2(전진) → y~x2(후진) → y~x2+x3(전진) → Stop