오후 : 회귀분석
< 가설검정 >
가설검정 단계
- 가설을 수립
- 유의수준 결정 : 모수의 추정이 맞지 않을 확률을 결정 (일반적으로 5%로 설정)
- 기각역 설정 : 가설의 기각여부를 결정하는 범위계산 (유의수준이 결정되면 자동적으로 계산됨)
- 통계량의 계산 : 표본의 통계량을 이용해 가설검정
- 의사결정 : 기각을 할지, 못할지 결정
가설의 정의
- 가설 : 주어진 사실 혹은 조사하고자 하는 사실이 어떠하다는 주장이나 추측
- 귀무가설 : 연구자가 증명하고자 하는 실험가설과 반대되는 입자. (= 효과(혹은 차이)가 없다)
- 대립가설 : 귀무가설의 반대. 연구자가 실험을 통해 규명하고자 하는 가설 (= 효과(차이)가 있다)
양측검정 / 단측검정
- 양측검정 : 대립가설이 어떠한 특정 모수와 같지 않음을 검정
- 단측검정 : 대립가설이 어떠한 특정 모수 이상 또는 이하를 검정
검정통계량 / 유의확률
검정통계량 : 가설검정을 위해 사용되는 주요 표본 통계량
유의확률(p-value) : 귀무가설이 맞다는 전제 하에, 통계값이 실제로 관측된 값 이상일 확률
양측검정의 p-value는 절대값 사용 : P(|Z|>1) = P(Z>1) + P(Z<-1)
유의수준 & 기각역
- 유의수준 : 귀무가설이 실제로 참일 때, 귀무가설에 대한 판단의 오류 수준. 가설 검정 전에 정해야 함.
- 기각역 : 귀무가설을 기각하게 되는 영역
- 기각역에 검정통계량이 포함되는 경우 : 귀무가설 기각, 대립가설 채택
- 채택역에 검정통계량이 포함되는 경우 : 귀무가설 채택, 대립가설 기각
두 모집단의 비교 : 두 그룹의 표본의 크기가 크고 모평균의 차가 특정한 상수와 같은지를 검정
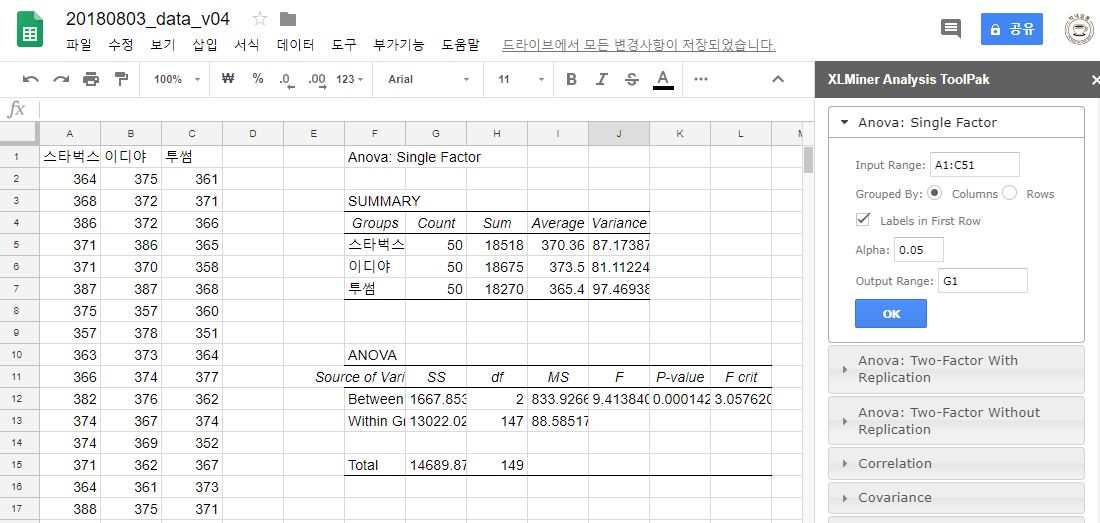
< 분산분석 : 실습자료 20180803_data_v04.xlsx @Google Spreadsheet>
분산분석
- ANOVA (Analysis of Variance)
- 3개 이상의 집단에 대한 평균 차이를 검정하기 위해서, 분산을 비교하는 분석 방법
- 집단 간의 분산과 집단 내의 분산을 확인하여 모집단의 특성을 찾아냄
- 총편차 = 집단 간 편차 + 집단 내 편차
- 집단 간의 분산이 클수록, 집단 내의 분산이 작을수록 집단 간의 평균차이가 커짐
- 분산비율 F
- 집단 간의 상대적인 비율을 확인한 것
- 분산비율 F = 집단 간 변동 / 집단 내 변동
- F값이 커질수록 집단간의 평균차이가 커짐
분산분석표
- 자유도(Degrees of freedom) : 모집단에 대한 정보를 주는 독립적인 자료의 수
- F분포 : 두 개의 자유도에 따라서 값이 달라짐
- Google Spreadsheet에서 분산분석 : 부가기능 XLMiner Analysis Toolpak 추가 필요
- XLMiner → Start → Anova 선택 → 데이터 범위, 첫 행 Label 여부, 출력할 셀 설정 → 실행
< 회귀분석 : 실습자료 20180803_data_v04.xlsx @Google Spreadsheet >
회귀분석
두 변수(독립/종속) 사이 관계의 통계적 유의미성을 검증하고, 그 관계의 정도를 분석하는 것
독립변수(= 설명변수) : 실험하는 사람에 의하여 통제되어 주어지는 변수
종속변수(= 반응변수) : 독립변수에 의하여 결정되는 변수
단순 선형 회귀분석 : 설명변수가 1개인 선형회귀모형. 2차원 면으로 표현.
다중 선형 회귀분석 : 설명변수가 2개 이상인 선형회귀묘형. 3차원 이상의 다면체로 표현.
최소 제곱 추정법 :
- 모든 관측치에 대해 실제 값과 예측 값의 차이를 계산하여 제곱한 값을 합함
- 제곱 값의 합이 가장 작도록 만드는 회귀식을 선택함
Google Spreadsheet에서 회귀분석 : XLMiner Toolpak 사용
- XLMiner → Linear Regression → 데이터 범위, 첫 행 Label 여부, 출력할 셀 설정 → 실행
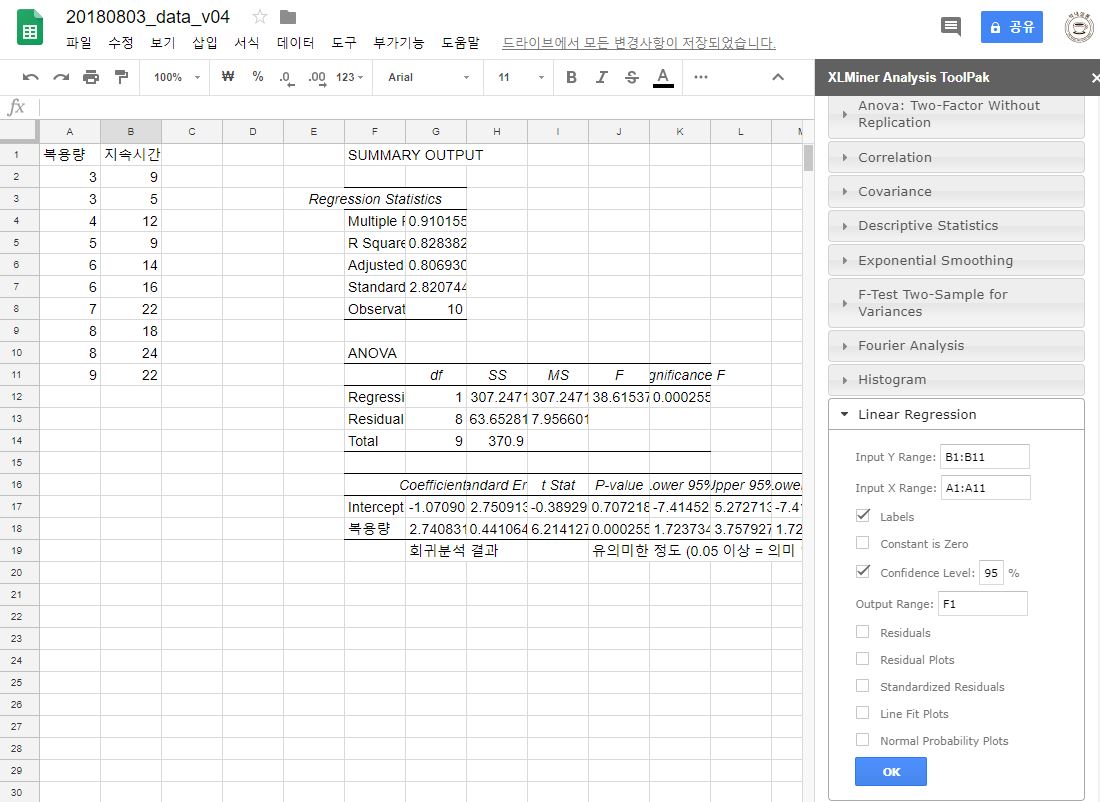
연속형 변수의 해석 : 독립변수 X가 한 단위 증가할 때, Y의 평균 변화량
범주형 자료의 회귀분석
지시변수 : 범주형 변수의 (class의 개수 - 1)개의 1,0으로 이루어진 변수로 전환시킨 변수
전체 범주를 한번에 회귀분석을 돌리면 오류가 발생
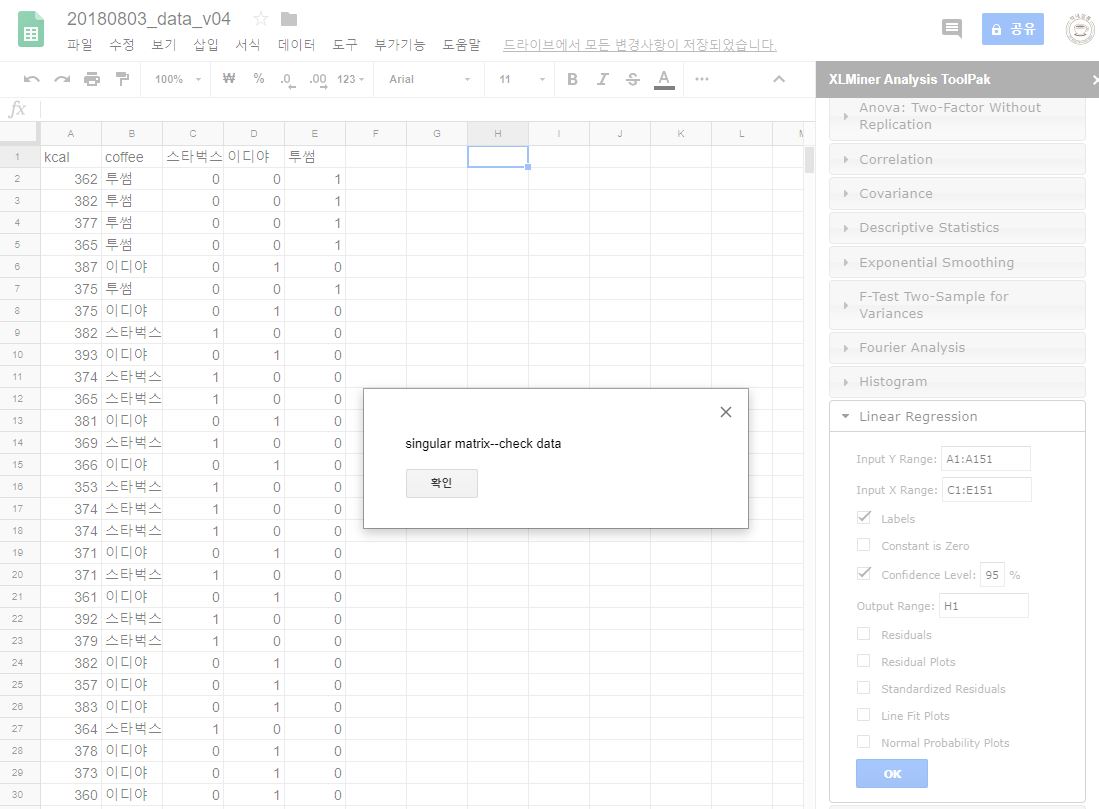
1개의 범주는 기본이 되는 범주로 고정하고, 나머지 범주에 대해 회귀분석을 실행
해석 : 기본이 되는 범주(= 회귀분석 안 돌린 범주)에 비교했을 때, Y의 평균 차이량
결정계수 (R-square)
- '추정된 회귀식이 X와 Y의 관계를 얼마나 잘 설명하는가?'에 대한 상대적인 값
- 반응변수(Y)의 전체 변동 중 예측변수(X)가 차지하는 변동의 비율